このページは、全国漢籍データベース協議会の公式ホームページです。
現在、幹事機関のひとつ、京都大学人文科学研究所 附属東アジア人文情報学研究センターが管理・運営しています。
【お知らせ】
・足利学校漢籍データを新規に登録しました。(2023年4月)
・実践女子大学図書館高橋良政文庫漢籍データの校正が終わりました。(2022年2月)
・福井大学附属図書館漢籍データを新規に登録しました。(2021年6月)
・椙山女学園大学図書館漢籍データの校正が終わりました。(2020年7月)
・京都府立大学附属図書館清水文庫漢籍データを新規に登録しました。(2020年5月)
(過去のお知らせ)
全国漢籍データベースは、日本の主要な公共図書館・大学図書館が所蔵する「漢籍」の書誌情報について、伝統的な「経・史・子・集」の四部分類(叢書部を加えて五部分類)に基づいて収集・登録した連合漢籍目録データベースです。全国漢籍データベース協議会は、このデータベースの作成事業に御賛同いただいた全国の図書館関係者によって2001年3月に組織されました。協議会では国立情報学研究所、東京大学東洋文化研究所
附属東洋学研究情報センター、京都大学人文科学研究所
附属東アジア人文情報学研究センターの3者を幹事機関に選定し、幹事機関のもとに全国漢籍データベース作成委員会を組織してデータベースの作成事業を推進しています。
平成13年度(2001)に始まった作成事業では、
第一期(五ヵ年)の終了時点において35機関、約62万レコード
第二期(五ヵ年)の終了時点において69機関、約81万レコード
のデータを構築し、これをウェブ上に公開しました。
一部、未校正のデータを含んでおりますが、これについてはすみやかに校正を行うとともに、今後とも引き続きデータの拡充に努めてまいります。
2018年4月現在のデータ件数、及びデータ容量は次のとおりです。
・登録機関:76機関(延べ数)
内訳は こちら をご覧ください。
・登録レコード:925185レコード(1138862KB)
・巻頭画像:14651枚(5306450KB)
データベースの仕様については、次の資料をご覧ください。
なお、京都大学人文科学研究所漢籍データのうち、一部のデータは全文画像データベース(東方学デジタル図書館)にリンクされています。
データベースに採録する「漢籍」の定義について、幹事機関の一つである京都大学人文科学研究所では、「中国人が中国語を用いて著した書物のうち、おおむね清代まで(辛亥革命以前)の人物が著した書物」を漢籍とみなしています(『漢籍目録――カードのとりかた』、2005年、朋友書店)。ただし、採録の範囲は参加機関の目録それぞれに異なっており、必ずしも統一が取れているわけではありません。一部、例外的には日本・朝鮮・ヴェトナム人等の著作を採録する場合もあり、また「新学部」に相当する著作を採録する場合もあることをご承知おきください。
全国漢籍データベース協議会では、2001年の創設以来、毎年、総会を開催し、全国漢籍データベース作成事業の進捗状況について報告を行っています。
また広く内外の関係機関の方々に御講演を依頼し、漢籍データベースの構築に関心を持つ方々の交流の場を提供しています。
(平成23年度以降、「年次報告書」の掲載をもって「総会」に代えております。)
全国漢籍データベースには、書誌学上の重要性に鑑みて『四庫全書總目提要』のテキストデータベースが併設されています。底本は「民國二十二年
上海商務印書館 排印本」です。
京都大学人文科学研究所附属東アジア人文情報学研究センターでは、旧東方文化学院京都研究所の収蔵漢籍(『東方文化学院京都研究所漢籍目録』1938年版)を対象に、教員有志による逐冊調査を行い、全国漢籍データベースの記載情報に関する確認・増補の作業を進めています。これは全国漢籍データベースに記載された書誌情報の典拠を示し、その正確性を確保すると同時に、蔵書印、題字、序跋などに関する追加情報をも提供するものです。体例、内容ともに不十分な覚書にすぎませんが、将来、他機関の収蔵する漢籍との比較調査を進めるうえで、基礎資料として活用されることを期待します。
(京都大学人文科学研究所所蔵漢籍の各データにリンクされています。現在、史部・子部の一部のデータが公開されています。今後とも逐次追加していく予定です。)
全国漢籍データベースと‘NACSIS-Webcat’は、それぞれデータベースとしての設計を異にします。このため、両者がデータを共有するには種々技術的な困難が伴いますが、これを克服して相互に参照可能なリンクを構築すれば、データベースとしての利便性は飛躍的に向上します。このため、現在、国立情報学研究所と京都大学人文科学研究所附属東アジア人文情報学研究センターの両者が共同して試行的な実験を行っています。
(現在、京都大学人文科学研究所附属人文情報学研究センター所蔵分6,517件について、NACSIS‐CATから全国漢籍データベースへのリンクが構築済みです。)
「全国漢籍データベース作成委員会」では、学術的観点から選定した公私の漢籍所蔵機関(主としてすでに冊子体の目録を公刊されている機関)のうち、漢籍データの使用をご許可いただいた機関の所蔵漢籍について、許諾日の順序に従ってデータ入力(電子データ化)の作業を行っています。
目録冊子(もしくは図書カード)の入力作業はすべて「全国漢籍データベース作成委員会」の責任において行い、その費用もすべて本委員会が負担します。作成したデータに関する諸権利はすべて当該漢籍の所蔵機関に帰属し、本委員会は「全国漢籍データベース」における公開の目的に限って当該のデータを使用します。作成したデータは「全国漢籍データベース」への登録・校正が終わり次第、すみやかに当該機関にお引渡しいたします。
今後、「全国漢籍データベース」への参加をご検討されている機関の方は、ぜひ、「全国漢籍データベース作成委員会」までお申し出ください。
冊子目録を持たない機関の方も、ご遠慮なくお問い合わせください。
*書名、撰者名、刊年、出版主体、請求番号、等の電子データ(エクセル・ファイル等)をご提供いただければ、比較的短い期日でデータベースに登録することができます。
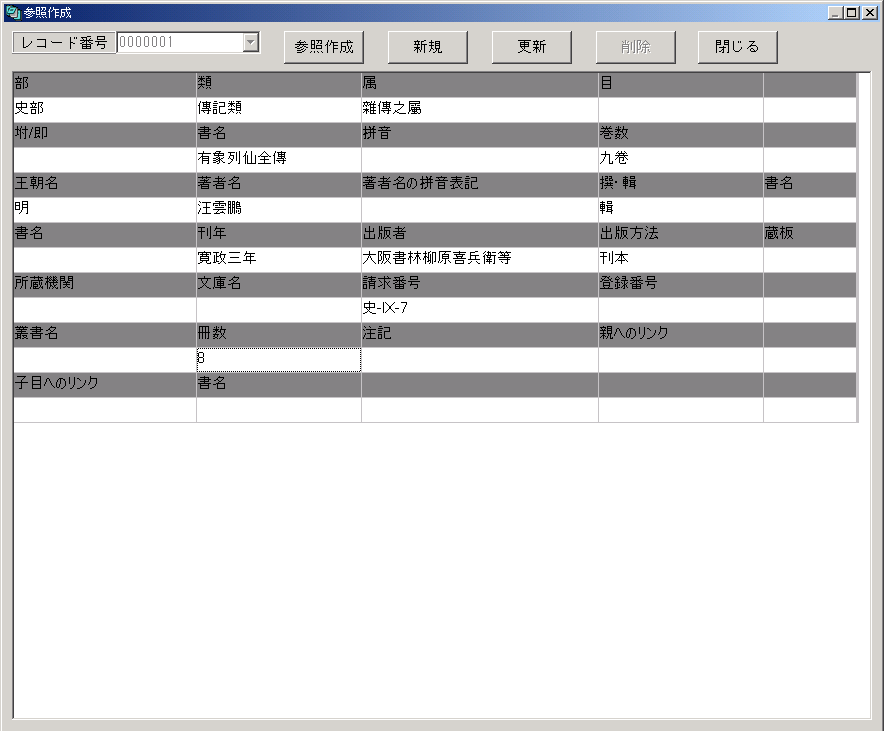
*より詳細なデータを作成される際には、ぜひ「漢籍レコードエディタ」をご利用ください。
このソフトは漢籍の書誌データを入力するために開発されたフリーウェア・ソフトです。このソフトによって、書名・撰者名・出版情報などを入力すると、そのデータがそのまま「全国漢籍データベース」の入力フォーマットに従ったデータとなります。作成したデータを「全国漢籍データベース作成委員会」にお送りいただければ、当委員会にて必要なチェックをおこなった後、すみやかに「全国漢籍データベース」に反映させることができます。
このソフトは京都大学人文科学研究所附属東アジア人文情報学研究センター主催の漢籍担当職員講習会(初級)における実習教材としても使用されています。実習においては、目録カードの作成と同時に、各項目をこのソフトに従って入力します。やや習熟された方は、目録カードを取ることなく、漢籍の現物を開きながらそのままデータの入力をされています。どなたにもご利用いただける、使いやすいインターフェイスを備えています。
なお、このソフトはWindows2000以上のOSで作動します。
なお、人文研漢籍データのご請求は、使用目的を明記のうえ、機関長名義の公印文書によって「京都大学人文科学研究所
附属東アジア人文情報学研究センター長」宛てにお申し出ください。
(個人の方からのご請求はお断りしております。悪しからず御了承ください。)
「全国漢籍データベース」は文部科学省全国共同利用・共同研究拠点に指定されている京都大学人文科学研究所において、拠点経費の一部の割愛を受けて作成しております。
「全国漢籍データベース」の作成は、下記の助成金により行われています。
平成25年度科学研究費補助金(研究成果公開促進費)、課題番号:258017
平成23年度科学研究費補助金(研究成果公開促進費)、課題番号:238016
平成22年度科学研究費補助金(研究成果公開促進費)、課題番号:228017
平成20年度科学研究費補助金(研究成果公開促進費)、課題番号:208023
平成19年度科学研究費補助金(研究成果公開促進費)、課題番号:198027
平成18年度科学研究費補助金(研究成果公開促進費)、課題番号:188034
平成17年度科学研究費補助金(研究成果公開促進費)、課題番号:178028
平成16年度科学研究費補助金(研究成果公開促進費)、課題番号:168033
平成15年度科学研究費補助金(研究成果公開促進費)、課題番号:158033
平成14年度科学研究費補助金(研究成果公開促進費)、課題番号:148046
平成13年度科学研究費補助金(研究成果公開促進費)、課題番号:13812
全国漢籍データベースに関するお問い合わせは、下記のE-mailにて受け付けております。
データの改訂・修正に関するご意見もお寄せください。
ただし、データベース掲載漢籍の閲覧・利用に関する事柄は、各所蔵機関に直接お問い合わせください。
(当会では漢籍の内容に関する照会は受け付けておりません。)
E-mail: kanseki@kanji.zinbun.kyoto-u.ac.jp
{kind=link}