
 to Home Page
to Home Page
コンピュータによる敦煌文献の校合
図入りの事例研究 ウルス・アップ
梗概
本記事(電子達摩第4号にも収録されている)は、最初期の中国禅文献の一つである『修心要論』のいくつかの写本の電子版を、コンピュータによる校合ができるように印づけするための簡単な印づけ手順についての事例研究である。校合プログラムには、マッキントッシュ上のCollate 2.0 を使用した。
はじめに
これらは、1994年の後半における筆者の研究過程の一つから得られた印象である。その目的は、中国の古写本をデジタル媒体に変換するのをテストすることにあった。その過程で、私は単にテキストの精神だけでなく、写本本体そのものをも尊重し大切にすることを学んだ。そこには判読困難な文字、異体字、誤字、訂正、削除、脱落、空白、破れ、その他様々な欠陥がある。それらは何かを語るものであり、デジタル媒体は印刷媒体より遙かによくこれらの声を聞き、尊重することができるのである。これらのテキストに耳を傾け、その本体に語らせることは極めて重
要であると思う。ヨーロッパのテキストクリティックの技法が明らかにしてきたように、「良く」ないもの、その欠陥は、我々が考えるより多くのことを教えてくれることができる。敦煌学においては、今もなお、その努力の大半は様々な「キズのある」原典から「良い」テキストを得ることにある。
しかし、異体字や空白や訂正などの特異性(あるいは「異常性」)は、電子媒体に変換されるべき価値がある。なぜなら、それらはテキストについて「正常」であるものより多くのことを語ってくれることがよくあるからである。実際、クリティカルテキストを編集する技術の全体が、「良いテキスト」よりもむしろ誤記や異常性に大きく依存している。というのも、これらの欠陥こそ写本の伝承や派生関係を追跡することを可能にしてくれるからである。印づけのされた電子ファイルは、印刷媒体において全く無視される傾向にあった異常性を記録し、整理する多くの
可能性を開くものである。
本計画は、技法習得を目的とした予備的テストにすぎなかった。より正確な分析や実りある印づけのためには、テキスト印づけ推進会(TEI) の草稿に関するP3のガイドラインに従うべきである。しかしながら、ここに紹介するような初歩的な印づけの方法でさえ、全体的な問題と、取り得る解決策について、いくばくかを学ぶことができるであろう。筆者の使った方法は、デザインのためよりも、むしろ便宜性を考えたものである。筆者は、ただ、多くのテキストを研究し、Collate 2.0 のプログラムを使って、それらを校合したかっただけなのである。
1 原本
ここでは、例として『絶観論』『修心要論』を使おうと思う。これらはともに今世紀初頭、ゴビ砂漠の敦煌莫高窟で発見されたものであり、そこに百年以上眠っていたのである。その大部分は、マイクロフィルムの形で手に入れることができるが、いくつかのものは入手困難である。私は石井本といくつかの例の原典の複写を柳田聖山前所長から借り受けることができた。しばしば、原物を見ることが重要なことがある。たとえば『修心要論』により高密度の印づけをするために、私はパリとロンドンへ行き、原物を調査した。これは極めて興味深い経験であった。とい
うのも、そこには多くの訂正、破れ、かすれた部分、紙質、インクの相違など、マイクロフィルムの複製では分からないものがあったからである。
2 異なる写本を概観し、順序づけること
まず最初に、異なる写本ないし断片を基本的な順序づけを行なうために概観しなければならない。順序づけには〈 〉で仕切られた番号(たとえば〈10〉のように) を使う。これは、プログラムによる校合には必要なのである。プログラムには何を比較すべきかを知らせてやらなければならず、プログラムはそれによって対象となっている写本の同一番号のものについて、全テキストを比較するのである。
テキストの脱文を表示するために、空の番号(番号のみ)を与える。同時に写本とテキストの物理的特徴についても概観しておかねばならない。これに基づいて電子テキスト版において印づけすべき事柄の予備的リストを設定することができる。実際に入力された場合、それは次のような具合になるだろう。(〈2 〉と〈3 〉の間に脱文のあることに注意。2 バイト文字のg は外字の代替文字である)

この例で使われている&P1&はページマーカーであり、&L1&はラインマーカーである。
3 最も完全な写本を入力すること
写本の概観が一通りすめば、次にそれを基本入力に使わねばならない。この目的のためにには、最も完全なテキストを選ぶのが最良である。ひとたびこの入力がすみ、校正し、順序づけの印が挿入されれば、いくらでも必要なだけのコピーを作り、そのファイル名を変更し、それぞれの写本原典に応じて、それらのファイルをカットし校訂してゆくことができる。従って、入力する必要のあるのは、一つの写本の全体のみである。
4 異なるファイルの編集
今や、すべての入力ファイルが、コンピュータ上で編集できる。まず、コピーしたファイルの行替えをすべて取り去り、それぞれの原本に従って正しい位置に行替えを付け加える。さらに頁の始まり(&Pxx&) 、節の始まり、その他関連する構造上の情報を印づけする。行替えを挿入するかぎり、行番号は必要ない。プログラムは自動的に行を数えることができるからである。それぞれのファイルを原本と比較しながら、写本の特徴を反映するさまざまな印を付け加える。この電子的に文字や文章に印づけする方法は、電子テキストの質を相当に向上させる。たとえば、あ
とで文字の反転や訂正などについては、検索することができるのである。
私は、次の特徴を印づけすることのできる簡単な印づけセットを開発した。(これは一つの規範として提示するものではなく、急いで集めた一つのグループにすぎないということを注意しておきたい。よりよい印づけセットは、TEI のガイドラインに沿うべきである。Collate の最新版のあるものは、これをサポートしているかもしれない)
- 文字のサイズ、書式(次の例に見られる細字による答のような場合)。ここでは文字のサイズの違いは重要である。というのも、このスタイルで書かれた答を持つ現存写本はいくつかに限られているからである。

- 異体字のような特別な文字の形

- 判読困難な文字

- 完全には読めないが、推理可能な文字

- 行間に付加された訂正

- もとの文字を上書きした訂正

- 行間に挿入された記号によって倒置された文字

- 印や記号(もちろん、それぞれの種類に対して異なった記号で印づけしてもよい)

- 訂正の印、強調の印など

- 文字を塗りつぶすことによる訂正(写筆者の注意深さを示すことにもなる)

- さまざまな種類の段落
- 紙の破れ
- 紙が貼り合わされた部分(行数によって紙の大きさを計算することを考慮すれば、紙を貼り合わせることによって訂正したことを示している)
- インクの特徴(他の部分とは異なるインクによって書かれたような文字は、改訂ないし修正を示している。
- 句読
さらに多くの特徴を印づけすることもできるが、ここでは以上にとどめておくことにする。これらのファイルを編集する際には、印づけを挿入するために、マクロ機能のあるエディタを使うことができる。印づけされたファイルは、大体次のようになるだろう。(r) 実際に書かれてはいないが、繰り返し記号によって表現されている文字を表す。(c) 付加による訂正を表す。(d) 不確かな読みを表す。(v) 異体字を表す、など。

5 第1次校正過程
それぞれの写本のコピーはここで、ファイルのプリントアウトと比較される。原本に近いサイズの縦書きのプリントアウトは、校正読みを、より速くより正確なものにする。これはかなり労力を要する過程であり、特に多くの写本を使っているときにはなおさらである。しかし、全体としてのデータの質は、この集中的な努力に負うところが極めて大きい。校正読みの間に、印づけをもう一度原典と照らし合わせて確認し、ユーザーの使用している地域的文字コードに含まれていない文字に対しては、一貫した代替記号を入力する。
6 第2次校正過程
2番目のプリントアウトを作成し、修正する。異体字や写本の特殊な特徴、それに判読不能ないし困難な文字に対して、特に注意する。それらは、パリ、ロンドン、レニングラードなどの原敦煌写本と照らし合わせて確認しなければならないかもしれない。これらを別々に印づけすることによって、それらの原典を調べるのをずっと容易にする。私はポータブルを読書室に持参し、行番号を付けるエディタを使用して、問題の場所を即座に探し出すことができた。
次に、プリントアウトの訂正をもとにして、コンピュータファイルを編集する。
7 原本の照合
マイクロフィルムや複製をもとにしては解決することのできない問題については、すべて原本を照合しなければならない。汚れや裏面の書込み、色、様々な種類の訂正、区切り線、使用の痕跡、一回分のインクで書かれた文字数などの物理的特徴に注意しなければならない。書写における誤記やその他通常の「良い」テキストの版本では無視される特徴に特に注意する。ついで、これに従ってコンピュータファイルを編集する。
8 さまざまなファイルのテスト校合
オックスフォード大学のCollate 2 プログラム(『コンピュータと異本計画』のピーター・ロビンソンによる)を使っていくつかのテキストをコンピュータで比較する。もし、より以前の「決定版」も入力されているなら、それを任意の数原本と比較することができる。これはコンピュータファイルと「決定版」の両方において誤りを見つけるための良い方法である。このような予備的な校合は、またテキスト間の関係を明らかにするのに大いに役立ち、印づけと順序づけにおける誤りを検出するのにも有効である。
9 テキストのプログラムによる校合
ピーター・ロビンソンのCollate 2 プログラムには、極めて多彩な出力オプションが用意されている。たとえば、「整列校合」を生成することができるが、これはすべての(あるいはいくつかの)テキストを整列させ、翻訳や全体的な比較には非常に便利である。このプログラムは日本語あるいは中国語に対してもうまく機能するが、そのためにはすべての文字と文字の間にスペースを挿入しなければならない。等幅フォントに設定すれば、きれいな整列化された出力を得ることができる。

このような整列化された出力は、翻訳や研究にとって非常に役に立つものである。
もちろん各人の好みに応じて、他の任意の形式を工夫することもできる。たとえば、異文だけを書き出し、相違の発見された他のテキストの正確な場所をプリントすることができる。

このプログラムは、また、どのテキストと比較し校合すべきかを自由に選択することができる。任意のテキストをマスターテキストとして使うことができ、これを他のテキストと比較することができる。次の例では、ただ二つのファイルのみを用いた。
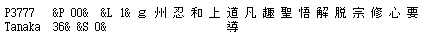
異文の開始点と終止点を識別するために、上付の番号の付いたマスターテキストを生成することもできる。また、テキストと、TEI フォーマットやそれに類するものにおける様態でプリントすることを選択できる。このフォーマットでは、マスターテキストは、次に示すような形で自動的に印づけられる。

この場合、クリティカルアパレイタス( 比較情報) もまた対応する様式で生成される。
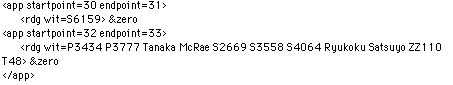
この例の場合では、比較情報によって、テキストの列全体は、アンカーNo.32 と33の間に見られる文字を含んでいないことがわかる。
結論
この種類のテキスト処理は、電子テキストの持つ多くの新しい可能性の一つを明示している。これによって研究者は、テキストから離れたものではなく、テキストそれ自体の一部として、内容や構造の分析を埋め込むことができる。ここにあげた例が示すように、これは研究目的にとって、極めて有用である。印づけを付加することを通して、電子テキストははるかに、印刷されたテキストより知的で多彩なものとなる。もちろん、長持ちし、確固とした規格を持つような印づけをすることが重要である。結局のところ、我々は自分たちの努力が他の人々の役に立つよう
なものであってほしいのだ--たとえそれが今から何百年もの間、生き続けようとも。デジタルテキストは、この点において、全く新たな可能性の世界を開示してくれるものである。
Author:Urs APP
Last updated: 95/05/04