
 to Home Page
to Home Page
Computerized Collation of a Dunhuang Text
An illustrated case study by Urs APP
Abstract
This article (which is also published in the Electronic Bodhidharma No. 4) is a case study of a simple tagging procedure to mark up electronic versions of several handwritten manuscripts of one of the earliest Chinese Zen texts, the Xiuxin yaolun (Jap. shuûshin yôron čCęSóvň_), in order to prepare it for computer-driven collation. The collation program used was Collate 2.0 on a Macintosh.
Introduction
These are some impressions of one branch of my efforts during the second half of 1994. Their aim was to test the transfer of ancient handwritten Chinese manuscripts to the digital medium. I learnt to respect and cherish not just the spirit of the text but also its body: the illegible characters, the variant forms, the mistakes of the scribes, the corrections, the deletions, the oversights, the spaces, the holes, and various other kinds of imperfections. They have something to say, and the digital medium is
far more capable of hearing and respecting them than print.
I think it very important to listen to these texts and to let their bodies speak, too. As the European text-critical approach has shown, what is not "good" about them, their imperfections, can teach us more than we think. In Dunhuang studies, most of the effort still goes into producing a "good" text from various "flawed" original source texts.
But particularities (or "abnormalities") such as variant characters, spaces, corrections, etc. merit being transferred to the electronic medium just because they often tell us more about the text than what is "normal." Indeed, the whole science of critical text editions relies heavily on mistakes and abnormalities rather than "good text" since it just these imperfections that allow us to trace manuscript traditions and filiations. Electronic files with embedded tags open up many possibilities of recording a
nd processing abnormalities that tended to be ironed out in the printed medium.
This project was just a preliminary test for learning purposes; for more precise analysis and fruitful tagging, the Text Encoding Initiative's P3 guidelines for manuscripts should be followed. However, even with a primitive tagging method such as the one presented here, one may learn something about the overall problem and possible solutions. The method I used was one of convenience rather than design; I simply wanted to study a number of texts and collate them using the Collate 2.0 program.
1. The original manuscripts
I will here use examples from the Ishii manuscript of the Jueguanlun (jap. Zekkanron) and the Xiushin yaolun (jap. Shûshin yôron). Both were found at the beginning of this century in the Dunhuang manuscript cave in the Gobi desert where they had slept for over 100 years. Most are available in microfilm format, but some are hard to get. I could borrow a reproduction of the Ishii manuscript, the source for some examples, from Prof. Yanagida Seizan. Often, seeing the originals is cruc
ial. For more intensive tagging of the Xiuxin yaolun, for example, I went to Paris and London to inspect the originals. This was an extremely interesting experience as there were many corrections, holes, blurred passages, paper characteristics, differences of ink, etc. that are impossible to gather from microfilm reproductions.
2. Surveying and sequencing different manuscript versions
First, one has to survey the different manuscripts and fragments in order to establish a basic sequence, using numbers delimited by <> (for example <10>). This is necessary for the program-driven collation; the program must know what to compare, and it compares all text that follows the same numbers in the used manuscripts. Text lacunae must be noted and given empty sequence tags. At the same time, one must make a survey of the physical characteristics of the manuscripts and their text. Based on this, one c
an establish a preliminary list of items that ought to be marked up in the electronic text versions. Once they are input, this may look something like this (note that there is a lacuna between <2> and <3>; the double-byte letter g is a gaiji placeholder):

Other information present here includes &P 1& as a page marker and &L 1& as a line marker.
3. Input of the most complete manuscript
Once the manuscripts are surveyed, one must use one of them for basic input. It is best to choose the most complete text for this purpose. Once the input is finished and corrected and all sequencing tags are inserted, one can make as many copies as necessary, rename the files, and go on cutting and revising those files according to their manuscript sources. So only one entire manuscript needs to be input.
4. Editing of Different Files
All input files are now edited on computer. First, one removes all returns from the copied file and adds returns exactly where they are in the original manuscript. Additionally, one marks page beginnings (&P xx&), chapter beginnings, and other relevant structural information. Line numbers are unnecessary as long as one inserts returns; the program can count lines by itself. While comparing each
file with the original manuscript, various tags are added that reflect the characteristics of the manuscript. This method of electronically marking characters and passages will increase the quality of the electronic text considerably; for example, one will later be able to search for character reversals, corrections, etc.
I developed a simple tag set that allows marking up the following characteristics (note that this set should not serve as a model but is just a hastily assembled group. Better tag sets should conform to the TEI guidelines which some later version of Collate may support):
- Size of characters, formatting (such as the answer written in smaller characters in the following example). Here, the difference in size is significant since only some of the extant manuscripts have all answers written in this style.

- Special characters forms such as variant characters

- Illegible characters

- Characters that are not completely legible but that can be guessed

- Corrections by interlinear additions

- Corrections by overwriting the original character

- Character reversal by an inserted interlinear symbol

- Marks and symbols (of course, one could tag each kind by a different symbol)

- Correction marks, marks of emphasis, etc.

- Corrections by blotting out characters (can also indicate care the writer took)

- Various kinds of indented text
- Holes in the paper
- Places where the paper sheets are glued together (allows to calculate sheet size in terms of number of lines, indicates corrections by pasting sheet parts)
- Ink characteristics (such as characters written in different ink from the rest, indicating revision or correction
- Punctuation
Many more characteristics could be marked up, but for now I will leave it at that. While editing the files, one can use an editor with macro capabilities to insert these tags. A tagged file might then look something like this; (r) stands for character that is not actually written but represented by a repetition sign, (c) for correction by addition, (d) for doubtful reading, (v) for variant character form, etc:

5. First proofreading pass
Each manuscript copy is now compared with a printout
of the file; vertical printouts similar in size to the
manuscript make proofreading speedier and more accurate. This is a rather laborious process, especially when there are many available manuscripts; but the overall quality of the data depends very much on this concentrated effort. While proofreading, the tags are once more verified against the original,
and uniform placeholder symbols are input for characters
not present in the national character code that one uses.
6. Second proofreading pass
An second printout is made and corrected. Special attention is paid to variant characters, peculiar characteristics of the manuscript, and illegible or hardly legible characters. They may have to be verified against the original Dunhuang copies in Paris, London, Leningrad, etc. Marking them off in separate ways makes consulting these originals much easier; I took a portable to the reading rooms and could look for the problem spots right away, using an editor which numbers the lines.
The computer files are then edited on the basis of the corrections on the printouts.
7. Consultation of the originals
For all issues that cannot be solved on the basis of microfilms or copies, the original manuscripts must be consulted. Physical characteristics of these manuscripts such as stains, writing on the back, color, various kinds of correction, lineation, traces of use, number of characters written with one replenishment of ink, etc. are noted. Particular attention is paid to mistakes by scribes and other characteristics that usually are ignored in printed editions of a "good" text. The computer files are then edi
ted accordingly.
8. Test collation of the various files
Using Oxford University's "Collate 2" program (by Peter Robinson of the ŚComputers and Variant Texts Projectą), some of the texts are compared by computer. If earlier "critical editions" were also input, they can be compared to any number of original manuscripts. This is a good way of finding mistakes both in the computer files and in the "critical editions." Such preliminary collations also can shed much light on textual relationships and also serve to detect mistakes in tagging and sequencing.
9. Program-driven collation of the texts
Peter Robinsonąs "Collate 2" program has extreme versatility of output options. For example, one can produce a "lineated collation" which lines up all (or just some) texts and is very useful for translation and overall comparison. The program works well with Japanese or Chinese data, provided that one inserts a space between every character and its neighbor. If one sets the font to an equal-width font (tohaba in Japanese) then one gets nice lineated output.

Such lineated output that can be very useful for translation and study.
One can of course devise any other format to one's liking. For example, one can have only variants written out and print the exact places in other texts where differences are found.

The program also allows one to freely choose which texts ought to be compared and collated. Any text can be used as master text with which the others are then compared. In the following example, I used only two files.
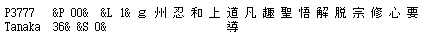
One could also generate a master text with superscript numbers to identify starting and ending places of variants, and one also has the choice of printing text and apparatus in TEI format or something close to it. In that format, the master text is automatically marked up as shown;

the critical apparatus is in this case also generated in a corresponding format:
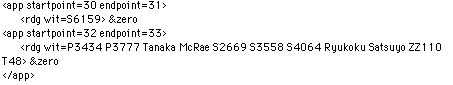
In this case, the apparatus states that a whole row of texts do not contain the character that is found between anchors no. 32 and 33.
Conclusion
This kind of text processing demonstrates one of the many new possibilities of electronic text. It allows researchers to embed analysis of content and structure as part of the text itself, not divorced from it. This can be extremely useful for study purposes, as the present example shows. Through the addition of markup tags, electronic text becomes much more intelligent and versatile than printed text; of course, markup with a long lifespan and solid foundation is important. After all, we want our efforts t
o be of use to others -- even if they live hundreds of years from now. Digital text opens up a whole new world of possibilites in this respect.
Author:Urs APP
Last updated: 95/05/04