 The concordance table (four gospels) of a handwritten bible
The concordance table (four gospels) of a handwritten bible

 to Home Page
to Home Page
���̔�������A���悻���N�O�A���l���̒����l���A���������̋L�^�Ɏg����ƋC�Â��܂ŁA�����Ȏ��Ԃ̌o�߂��K�v�ł������B�����I��A�鍑�ɂ�����L�^�}�̂Ƃ��āA�������łɎ嗬�ƂȂ邱�ƂȂǁA�ނ�ɂ͎v�����y�ʂ��Ƃł������B���͎����I�ɃC���h�ɂ킽�邪�A�C���h�l�������V�����}�̂̐��ݔ\�͂�F������ɂ́A���悻�ܕS�N��v�����B
��\���I�ɁA���߂ă��[���b�p�l��������H�Ƃɂ���Đ��Y���͂��߂��Ƃ��A�ނ�͂����r�玆�̈����ȑ�p�i���ƍl���Ă������A�O�[�e���x���O�̔����ɂ���āA���Ƃ����}�̂́A�N���\�����ʕ����ւƓW�J���Ă������B�P�W�O�O�N�ɂ́A�h�C�c�ɂ����鎆�̑����Y�ʂ́A�N�Ԉꖜ�ܐ�g���ł��������A�P�X�O�O�N�ɂ́A���łɔ��\���g���ɂȂ�A����Ɏl�����I�̌�ɂ́A�N�ԓ�S���g���ɒB���Ă����B�����Ƃ���ł́A���ł̓J���t�H���j�A��w�����ŁA��L�����[�g���̏��I�ɑ��������������A�N�X�A���o���Ă���B
�����A���̗��j�����Q�̘A���ł���Ȃ�A���܂��̂Ƃ��ɐ��܂ꂽ����́A�V�����}�̂ɂ��ẮA�y���ɑ傫�ȋ��Q�ƂȂ邱�Ƃ��A���炩���ߗ\���ł���B�킸���ɐ��\�N�O�ɂ́A�f�W�^���L�^�ƃf�W�^�������́A�����A���������̐��w�҂Ƃ��̑��̐����}�j�A�̊S���ɉ߂��Ȃ��Ǝv���Ă����B
�����A�����͋����قǗl�X�ȕ��ʂŁA���łɎ��p������Ă���B���Ƃ��A�S�����甭����M�����������āA�K�v�ȂƂ��ɓd����S���ւƑ��鑕�u�i�S���̃y�[�X���[�J�[�j��A�����̋L�^�ƍĐ��i�R���p�N�g�f�B�X�N�j�A�f��̋�����E�\�����邱�Ɓi�f�W�^���摜�����j�A����ɂ����W�t�̑S��^�̍������쐬���邱�Ɓi�f�W�^�����������j�B
���̎g�p��������L���X�g���ɗ^�����e���f���悤�Ɗ�Ă邾���ŁA�S�͂����낮�B�܂��āA�f�W�^���}�̂̏ꍇ�A�ǂ��ɂ䂩��Ƃ��Ă��邩�͌����܂ł��Ȃ��A��X�����܂ǂ��ɗ����Ă���̂��f���邱�Ƃ�������ł���B�d�q�B����O���ŏЉ���T�ς������Ă���悤�ɁA�����̕������邢�͉摜�̃f�W�^������ڎw���������̌v�悪�A���łɐi�s���ł���B
�������A�����Ƃ����x�̌v��ł����A�قƂ�Lj���e�L�X�g�̖͕�Ȃ����g���̈������̂ł͂Ȃ��A�����A�����\�͂����ǂ���A��荂���ɏ����ł���ɉ߂����A�őP�̏ꍇ�ł��A�Ȃ�炩�̃n�C�p�[�e�L�X�g���邢�̓r�f�I�����N���\�ƂȂ��Ă���ɉ߂��Ȃ��B���ꂪ���ׂĂȂ̂��A�Ɠǎ҂͔��₷�邩������Ȃ��B����͎��X�ɂ��Ȃ��Ă���\�\�������A���́u���v�́A�Ñ㒆���l���A���߂Ď��̏�ɂ������̕������������u���v�ɕC�G������̂ł���B
�`�B���邽�߂ɂ́A�܂��������炩�̕��@�ŃR�[�h������K�v������B�R�[�h���ɂ́A�A���t�@�x�b�g�Ƃ��A�����̍c��A�`�̎n����ɂ���Đ��肳�ꂽ�W���I�ȕ����l����A�R���s���[�^�̃A�X�L�[�R�[�h�̂悤�ȁA���̌Œ肵�������K�v�ƂȂ�B��ʘ_�Ƃ��āA�R�[�h�͒�`�̎d���ƁA�P�����ɂ����āA������Ă������قǁA���ۂ̒ʐM�ɂ����Ė��ɗ����Ƃ���������ƌ����Ă悢�B
�I���ƃI�t�A���邢�͂P�ƂO�����g��Ȃ��Ƃ����A�f�W�^���I�ȃR�[�h���̎��P�������̂��̂��A�ʐM�ɂ����鋐��Ȑ��ݓI�\����������Ă����B�i����T�[�r�X�ɂƂ��āA�ݕ������炵��������i�ł���̂ɍ������āA�f�W�^���I�ɃR�[�h�����ꂽ���́A�������ɂ����āA�ɂ߂ď_��Ȏ�i�ƂȂ�B������A�Î~�摜�Ɠ���A�e�L�X�g�Ȃǂ́A���ׂăf�W�^���̌`�ŕۑ����A�ʐM���邱�Ƃ��ł���B�u�}���`���f�B�A�i���}�́j�v�Ƃ����p��́A���̈Ӗ��ł͌�������O�̕t�������ł���B�Ȃ��Ȃ�A���̂����Ƃ������ȓ����́A������̃��f�B�A� i�}�́j�A���Ȃ킿�f�W�^���I�}�̂������݂��Ȃ��Ƃ����_�ɂ��邩��ł���B
�V�����R�[�h�̑g�D�́A�ގ��̕����ɓW�J���Ă䂭�X��������B�ȉ��ɂ����āA�������̒N�������łɓ����ł���R�[�h�A���Ȃ킿������̃R�[�h�̔��W�ߒ����������A�f�W�^���e�L�X�g�̃R�[�h�Ƃ����A�V�������܂ꂽ����̃R�[�h�Ƃ́A�������̗ގ������w�E�������B
�菑���}�̂������}�̂ւ̈ڍs�A����Ɍ��݂ł͈���}�̂���f�W�^���}�̂ւ̈ڍs�́A�����̏d�v�ȕω������B�W�O�O�N�O��ɏ����ꂽ�A�L���ȁw�P���Y�̖{�x�́A�R�[�f�b�N�X�i�Îʖ{�j�A���Ȃ킿�Ԃ���ꂽ�{�̍D��ł���B�������A��X���{�Ƃ����Ƃ��ɃC���[�W��������̑������A����ɂ͌������Ă���B���Ƃ��A�ʕM�҂��N���A����Ƃ��N����������Ȃ����A���̖{���ǂ��Ő��삳�ꂽ�̂���������Ȃ��i�A�C�������h�̃P���Y�Ƃ����̂́A�����ɉ߂��Ȃ��j�B
The concordance table (four gospels) of a handwritten bible
���̖{�̖`���ɂ́A�u�R�[�f�b�N�X�v�A���Ȃ킿�p����������Ă��邪�A�����ɕt����ꂽ�ԍ��́A�e�L�X�g�ɂ��ĂȂ��̂ŁA�]����ɗ����Ȃ��B�y�[�W�ԍ����S���Ȃ��A�������菑���ł͂���̂����A���Ȃ�Ȃ����@�ŃR�[�h������Ă��邽�߂ɁA�ǂ݉����͔̂��ɍ���ł���B�ȗ��́A�l�X�ȋL���ŕ\������Ă��邵�A��ƌ�̊Ԃ̋͂Ȃ����Ƃ��������AU�� V�Ƃ����������͋�ʂ���Ă��炸�A�啶���E�������͋K�����Ȃ��g���A��Ǔ_�͓���݂̂Ȃ����̂ł���A���̏����͂Ƃ��ǂ��t�ɂȂ��Ă��铙�X�B
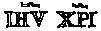 Examples of some common manuscript abbreviation codes
Examples of some common manuscript abbreviation codes
���̂悤�ȏȗ��L��(=Iesum)�ɒ��ӂ��Ăق����B
 �w�P���Y�̖{�x���
�w�P���Y�̖{�x���
�{�Ɍ����鎚��́A�菑�������ɍ������Ă���B�O�[�e���x���O�Ȃ������̓�����l�����́A�菑�������Ɍ�����悤�Ȗ{���쐬�����������i17�ŎQ�Ɓj�B���̂��߂ɁA�ނ�͂����P���Ɏ菑���R�[�h��p�����̂ł���B���傤�ǁA�����A�قƂ�ǂ̃R���s���[�^���[�U�[���A�f�W�^���e�L�X�g����������ہA�A���H�̊ϓ_�����Ǝ҂̃R�[�h��p���Ă���悤�ɁB
�����̈���R�[�h�̊�b�����o�����߂ɂ́A�����Ղ�S�N�ȏォ�������B�܂��A��{�I�ȃR�[�h�v�f�i�����j�����A�O�[�e���x���O�̔����̒������Ȃ��蓮�̎��꒒�����u�ɂ���č쐬���Ȃ���Ȃ�Ȃ������B�O�[�e���x���O�́A�{���I�Ɏ菑��������͕킵���̂ŁA���K�`���A�i�����j��ȗ��R�[�h�ȂǁA�����̓��ʂȗv�f�𗘗p�����B�O�[�e���x���O�̈���R�[�h�̊��S�ȃZ�b�g�́A�ŏ��A�R�O�O�̈قȂ鎚�ꂩ��Ȃ��Ă����B���̐}�́A��{�����i���i�j�A���K�`���A�i����i�j�A��Ǔ_�Ȃǁi���i�j����Ȃ�A�O�[�e���x���O�̙ˑ�ȕ����Z�b�g�̂� ���ꕔ�����������̂ł���B
����p�͋}���Ƀ��[���b�p�S�̂Ŏg����悤�ɂȂ��Ă܂��Ȃ��A�ŏ��͉ӁX�̉�Ђ̂Ȃ��ŁA���ɍ�������э��ۓI�ɁA��{�I�ȗv�f�̒P�����Ɠ��ꉻ�̕K�v�����Ɋ������悤�ɂȂ����B�₪�Ĉ���Ǝ҂����̓O�[�e���x���O�̕����Z�b�g�̎l���̈�̕����ŁA��肭��ł���悤�ɂȂ����B
�ɓ��ɂ����Ă��A��{�I�v�f�i�����j��W��������w�͂ɂ́A�������j������B�Ñ���A���{���ǂ͂��ꂼ��A����I�ɕW�������̃Z�b�g�����������B�ߑ�ɂ����ẮA���{�̂ق��ɁAIBM �� �x�m�� �̂悤�ȉ�Ђ��A�R���s���[�^�p�ɁA�Ǝ��̕����Z�b�g���`���Ă���B
�܂̑��Ƃɂ���Ē�`���ꂽ�����Z�b�g�́A������A��p�ɂ�����W���ƂȂ��Ă�������B������r�b�O�t�@�C�u�iBig-Five�j�R�[�h�ł���B�O�[�e���x���O�̌�p�҂������A��Ђ⍑�Ƃ̋��E���āA����ɕ����������炵�A�W�������Ă������悤�ɁA�����A���{�A�����A�؍��̕����Z�b�g���u���ꉻ�v���悤�Ƃ���w�͂�������B
���̓w�͂́AISO 10464 �W���i���邢�͂��̉��ʃZ�b�g�ł��郆�j�R�[�h Unicode �Ƃ��āj�m���Ă��邪�A�S���E�Ŏg�p����Ă���قƂ�ǂ̕�����I�ɃR�[�h�����悤�Ƃ��鎎�݂ł���B�����̓��ꉻ�́A���ɋً}��v����ۑ�ł���B�Ȃ��Ȃ�A���ۓI�R�[�h�̕s���ꂩ�炭�鍬���́A�����̒n��S�̂��A�A���t�@�x�b�g�g�p���ɂ���ׂāA���ɕs���ȏ�Ԃɗ������Ă��邩��ł���B�i�����Ɏg�p����Ă����X�̃R�[�h�ɂ��ẮA�d�q�B����O���Q�Ɓj
�������A�菑���̊��K�ɌŎ����Ȃ����Ɓi�O�[�e���x���O�̃��K�`���A��p�~����Ƃ����悤�ȁj�́A��r�I�P���Ȏd���ł���̂ɑ��āA�����Ɋւ��邻��́A�y���ɕ��G�ł���B
���Ƃ��A�C�̍���呠�o�̔Ŗ��R���s���[�^�ɓ��͂���ہA�ŏ��̓�ւƂȂ�̂́A��ō��܂ꂽ�����̎��̂ł���B�d�q�}�̂ֈڂ��ɂ������āA�ǂ�قǂ̓��ꉻ�ƒP�������K�v�ƂȂ�̂��낤���B�ّ̎��́A�ǂ̂悤�ɏ���������悢�̂��낤���B�ǂ̂悤�Ȏ��̂��{���I�Ȃ̂��A�ǂꂪ�����҂̊S���������̂Ȃ̂��A�̂ċ����Ă�������邱�ƂɂȂ�Ȃ��̂͂ǂ�Ȃ̂��B
�P��╶�A�߂ȂǂƂ������A�e�L�X�g�̂��傫�ȒP�ʂ̃R�[�h�ɂ��Ă��܂��A�ŏ��͔�������Ȃ���Ȃ�Ȃ������B�ɂ������Ă����ƁA�M���V���̃e�L�X�g�́A�P��Ԃ��邢�͕��͊Ԃɋ����Ȃ��̂����ʂł���̂ɑ��A���[�}�̔蕶�ł͂Ƃ�����P��̊Ԃ�_�ŋ���Ă���B�������A�ʏ�̃e�L�X�g�ł́A�P��̋��E�͖�������ĂȂ��B
�����I�Ɣ����I�ɂ����āA���l���̐ٗ�ȃ��e����̏����肪�A���傤�NJO���l�����{��̃e�L�X�g�ɋ�����悤�ɁA�P�����邱�Ƃ��n�߂��B
���[���b�p�ł́A�̓����́A�\���I������ٓǂ��u������̂Ɍ���I�Ȗ������ʂ��������A�P��Ԃ̋��O�ꂷ��̂́A�\�����I���ȍ~�ł���B���݁A�ǂݏ����̂��߂ɁA���E�ŕ��ʂɎg���Ă���R�[�h�̑����́A�����ŋ߂ɍ��ꂽ���̂ł���B���Ƃ��A�������A���p���A�_�b�V���Ȃǂ́A���ׂď\�����I�ɍ��ꂽ�B
�e�L�X�g�̊�{�I�P�ʂ��R�[�h�����邱�Ƃ���A�����̍\���v�f���R�[�h�����邱�Ƃɖڂ��ڂ��ƁA���l�̔��W�����������ƂɋC�Â��B�s�̂悤�ȁA���Ɋ�{�I�Ȕz��̍H�v�ł����A�������A���S�Ȃ��̂Ɏd�グ�Ȃ���Ȃ�Ȃ������B
�����̈���{�́A�ʏ�A�e�L�X�g�Ɋւ��钐�߂��t�����Ă��邪�A�܂��ڎ��̂悤�ȕW���I�����͔����Ă��Ȃ��B��������̕W���I�v�f�����o�����܂łɂ͎��Ԃ�v�����̂ł���A�V�������K�͂������Ǝp���������B���Ȃ킿�A�{�̃J�o�[�i�ł������̂͂P�W�R�R�N�ł��邪�A�L���p�Ƃ��čŏ��Ɏg��ꂽ�̂͂P�X�O�U�N�j�A�w�b�_�[�A�t�b�^�[�A�r���A�͖����A�}�G�A�}�\�A�Q�l���ځA�t�^�Ȃǂł���B�\�������悤�ɁA���������v�f�́A���܂��A�����Ř_�������d�q�����̂��߂̃R�[�h���̌n�ł���A�W���I�ėp��Â�����iSGML�j�̈ꕔ���Ȃ��Ă��
�B
�������������A���̗l�X�ȗv�f���������߂ɂ́A�v�f�̑S�̓I�ȂȂ��������m�肳��Ȃ���Ȃ�Ȃ��B�y�[�W�ԍ��Â��́A�P�U���I���ɔ��B�������A�܂��L���p������ɂ͎���Ȃ������B���ɖڎ���}�ňꗗ�A�������Q�ƁA�������Q�ƁA���߁A���p�Ȃǂ��������B
����ꍇ�ɂ́A���ɑ����̈قȂ�ł����e�L�X�g�̏ꍇ�ɂ́A�����̔Łi�قȂ錾��ŏ�����Ă���ꍇ���܂߂āj�ɂ����Ă����͂������ł���悤�ɁA�ʂ̎�ނ̑Ή��t�����J�����ꂽ�B�����̏ꍇ�͏͂���ю��̔ԍ��A�M���V���ÓT�̏ꍇ�͒ʂ��ԍ��A���������̈ꎚ�����̏ꍇ�́A�吳�呠�̔ԍ��Ƃ���������ł���B
�ЂƂ��т������������Â��̌��p���Z�������A���͂₱��Ȃ��ɂ͂���Ă䂭���Ƃ͂قƂ�Ǖs�\�ł���A���Â������ɂ������Â��̃R�[�h��t����悤�ɂȂ����i�ʖ{�̉E�t�E���t�ԍ��A�����ԍ��j�B
<text> contains a single text of any kind, whether unitary or composite, for example a poem or drama, a collection of essays, a novel, a dictionary, or a corpus sample.
�{�̍����ނ́A�����������I�Ή����Ɍ��܂Ő����i�߂�B
���̂悤�ȁu�Ή��v�́A�܂��A�l�X�Ȍo�H�Ȃ��������W���܂�ł���B����b����������Ă���Ƃ��A��X�͕��ʁA��������ɖ��ߍ��܂�Ă��錋���W�ɏ]���B����́A���������̂Ȃ��̏ꏊ�������A�}�ŎQ�Ƃ⓯�ꕶ�����Q�Ƃ�A���̈ꎟ����ѓ������w������w�W�Ȃǂ̂悤�ȁA��{�I�Ȍ����W�ł���B
�Ƃ�����A�������������W�͕����̃��C�A�E�g�ɔ��f����Ă��邱�Ƃ�������i�ٖ{��ΏƓI�ɔz�u������A����y�[�W�����ɒu���悤�ȏꍇ�j�B�ʂ̌����W�Ƃ��ẮA�����̗l�X�Ȏ���敪�i�����̔łƂ����j�n�}�Ȃǁj�����邵�A���邢�͕����Ɋւ��邻�̑��̏����l������B�S�Ȏ��T�́A��{�I�����W�̎g�p��Ƃ��āA�i�D�̂��̂ł���B���ԍ����܂��A��̎��������ȏ�̏��ƌ��������ł���B
�`���I�ɁA�����͂قƂ�ǂ̏ꍇ�A���̍ŏ��̒P�ꂩ�A��Ɍ����w�P���Y�̖{�x�̂悤�ɁA�����̃j�b�N�l�[���ɂ���Ēm���Ă���B���ҁA��ҁA�ʕM�ҁA���邢�͑}�G�Ƃ́A�قƂ�ǂ��̖����������邱�Ƃ��Ȃ��B���̖{���A�Ǝ��̂��̂ł������B����p�ɂ���Ă͂��߂āA���s���̍^���̂Ȃ��ɁA��̍�i���ʒu�Â���K�v�������Ă����B���[���b�p�ł́A���t�͂��̖ړI�ɑ��āA���肳�ꂽ�`�ł������ɗ����Ȃ������B�����̏ꍇ�ɔ�ׂāA��������Ɋւ���{���I�ȏ��𒍋L���邱�ƂɊւ��āA���[���b�p�l�͗y���ɖ��ڒ��ł������B
�����ɂ���Ĉ�����ꂽ�ŏ��̚����́A�P�S�T�V�N�Ɍ���Ă���A�����ƈ���Җ���`���Ă���B�{�̑Ή��Â���R�[�h���́A���X�ɔ��W�������A�P�S�V�O�N�ȍ~�ɂȂ��Ă悤�₭�w�\������ʉ������B�䂤�ɕS�N�ȏ�̎��s����������āA��X�����ݒm���Ă���\��y�[�W�́A���X�ɔ��B�����̂ł������B
���̈�A�̎ʐ^�ɂ����āA�����ƔN�ォ��A�����A���Җ��A���҂̏ё��ցA����ɂ͔��s�ꏊ�ƔN��ƂƂ��Ɉ���҂̖��O�A�����Đ��ɂP�T�X�S�N�ɂ́A���݂̕\��y�[�W�Ƌ߂����̂ɂȂ��Ă���B
����ɁA�{�Ɋւ����{�I����ۑ����邽�߂̌��ʓI�ȑΉ��Â��̕��@���A�Ƃ�킯�}���قŁA�J�����ꂽ�B���ҁA�ҎҁA�����A���s���A���e�̃L�[���[�h�A�Ō����L�ҁAISBN�ԍ��A���̑��A���݂̖{�̉������Ɍ�������̂��J�����ꂽ�̂ł���B�{�̖{�̂��̂��̂̂ق��ɂ��A���܂��܂Ȃ��̂��A�{�ɂ��Ċw�Ԃ��Ƃ������邽�߂ɁA���o���ꂽ�B���Ȃ킿�A�\���J�o�[�A�|�X�^�[�A�J�^���O�A���s�ē��p���t���b�g�A�����ꗗ�A���Г��e�[�T�A���o����f�[�^�x�[�X�Ȃǂł���B
���������Ή��Â��̕��@�̊J���ƕ��s���āA�}���فA���X�A�W��������A�Ï��X�Ȃǂ́A�����ƔЕz�̂��߂̎{�݂��J�����ꂽ�B��������ɂ���ɂ́A��̊�{�I�ȏꍇ������B��͂��Ȃ��������̂Ƃ�����ɍs���ꍇ�ł���A������͕����̂ق������Ȃ��̂Ƃ���ւ���ė���ꍇ�ł���B�}�̂͑O�҂����҂ւƈڍs����X���ɂ���B���̌X���́A�����̓d�q�����v���ɂ����āA���ɒ������B
�����A�W�A�̓������A�Ŕ������ꂽ�T�����́A���������i�D�̗�ƂȂ�B�ŏ��A���{�́A���̌���ł��鍻���̓��A�ŁA�Ђƈ���̒T���Ƃ̎�ɂ���Ē������ꂽ�B���ɁA�͂��̌b�܂ꂽ�����҂����������A��������邽�߂Ƀp���A�����h���A�k���Ȃǂɍs�����Ƃ������ꂽ�B���̒i�K�ł́A�}�C�N���t�B�������B���A�����̌�����������𗘗p�ł���悤�ɂȂ����B���̂悤�ɂ��āA���������́A���g�߂ɂȂ�A��˂͂��Ȃ�L���Ȃ����B
�����ł́A�����̕����́A�e��̌`�ŏo�ł������Ɠ����ɁA�R�s�[�@�ŊȒP�ɕ��ʂł��銈���̃e�L�X�g�Ƃ��Ă����ʂ���悤�ɂȂ�A�b�܂ꂽ�������ŕ�����w���̎�ɂ�����悤�ɂȂ��Ă���B���̒i�K�ł́A���������e�L�X�g�̓f�W�^�������Ƃ��ė��p�ł���悤�ɂȂ�A�d�b����ʂ��Ď�ɓ���邱�Ƃ��ł���悤�ɂȂ邾�낤�B�������āA�����̕����́A�A�t���J���|���l�V�A���ǂ����̑��R���s���[�^�ɁA�قƂ�Ǐu���ɂ��Ă��̎p���������Ƃ��ł��A���������[�U�[�͂��̌��̕����f�[�^�x�[�X���ǂ��ɂ��邩�A���̏��݂����m��Ȃ��
ł��ނ�������Ȃ��B
������ɂ��邱�Ƃ��ł���l�X�̐����A����ɑ������Ă����Ƃ����X���́A�f�W�^�������ƂƂ��ɁA���̕������������A�p�����Ă䂭�ł��낤�B�f�W�^���}�̂́A�������̎�_�������Ă���B���Ƃ��A�R�ς݂ɂ��ꂽ�{�̃y�[�W���A���₭�J��Ƃ����悤�ȑ��삪�ł��Ȃ��B�������A�{�̎�v�ȗ��_�ł��邱�̕����I�Ȑ������܂��A���E�������Ă���B���Ȃ킿�A���[�̂��߂̏��I�̃X�y�[�X�͍��������A�{�̂��铖�̏ꏊ�łȂ���Η��p�ł����A���ɂ���l�������p�ł��Ȃ����ł���B�f�W�^�������ɂ́A������������͂Ȃ��A�����̐V�����
\���ɓ����J���i���̑啔���́A�܂����������̂�҂��Ă����Ԃł���j�B�V�����R�[�h�����o����悤�Ƃ��Ă���A���̍ŏ��̌`�̂������iSGML�� TEI�j�ɂ��ẮA�{���̂Ȃ��Ř_�����Ă���B
�M���V���̃A���t�@�x�b�g��A�f�W�^���R�[�h�̂悤�ȁA�R�[�h���ɂ�����v���I�i����O�ɂ����Ƃ��A�l�X�͂����낮���Ƃ������B���Ƃ��A�v���g���́A�������Ƃɑ��āA�\�N���e�X�̔��ɂ������B���̗��R�́A�Ƃ�킯�A�u�L������߂�v����ł������B�Ƃ����̂��A����́u���Ȃ�ʋL���̌`�������O�I�Ȏx���ɗ��v���āA�u����𗝉��ł��Ȃ��l�X�v�̊Ԃ�������܂��A���҂�����̌��������������ٌ삵���肷�邱�Ƃ�j�Q���邩��ł���i�p�C�h���X�j�B �ʕM�҂��A�V��������p�͎菑�������������̂��ƍ��o�����P�T���I�ȗ��A����p��
���閳���̍R�ق��L�^����Ă���B
�����A�ӂ����сA�f�W�^���Z�p�ɋ��낵���댯�������Ă��鑽���̐l�X������B���Ƃ��A�{�̏��łƂ����悤�ȁ\�\�B�������A�{�͐����c��B���傤�ǎ菑���������ł������悤�ɁB�������A���̖ڂ̑O�ɁA���܁A�L�͂ȓ��ނ��}���サ����B������ꂽ���̉\����y���ɒ�����A���{�I�ɐV������ނ̃R�[�h�����\�ɂ��镨���I�Ȍ`�Ԃ����������ނł���B
��蕡�G�ȃR�[�h���́A�\�����邱�Ƃ̂ł��Ȃ������\�����J���B����́A��������̗��j�������Ă���B���߂ĐV����������ꂽ�̂͂P�T�X�V�N�A�O�[�e���x���O�̎���A�S�\�N�����Ă���ł���A�w�p�I������s�������s����Ƃ������z�����܂ꂽ�̂́A�O�[�e���x���O�Ȃ����Ɠ�S�N�����Ă��炾�����B����̐��S�N�ɂ����āA�y���ɑ�ʂ��d�v�ȉ\�����A�f�W�^���}�̂ɂ���ĊJ����邱�Ƃ��^�����R�́A�ǂ��ɂ��Ȃ��̂ł���B

Part of Gutenberg's character set
 Some characters from the world's oldest moveable-type book (�`1234/41)
Some characters from the world's oldest moveable-type book (�`1234/41)
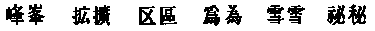
Some pairs of Chinese characters that are unified in Unicode
�P��

�I���O�P�S�T�N�A�M���V��
�v�f
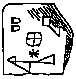 �s�̔����̑O�F�E���N�i���\�|�^�~�A�j�A�I���O�S�O�O�O�N����̗�B
�s�̔����̑O�F�E���N�i���\�|�^�~�A�j�A�I���O�S�O�O�O�N����̗�B
Top left: two / top right: temple, house / center: sheep / asterisk: god / bottom: Inanna
<front> contains any prefatory matter (headers, title page, prefaces, dedications, etc.) found before the start of the text proper
<body> contains the whole body of a single unitary text, excluding any front or back matter.
<back> contains any appendixes, etc. following the main part of a text
<div> contains a subdivision of the front, body, or back of a text
<div0> contains the largest possible subdivision of the body of a text
<div1> contains a first-level subdivision of the front, body, or back of a text (the largest, if
����
 Bocaccio�̃f�J�����l�̕\���i 1527�j
Bocaccio�̃f�J�����l�̕\���i 1527�j
�W�]
 ���[���b�p�̈�����̍ŏ��̊G�ł���A�w�_���X�}�J�u���x(1499-1500)���̖ؔłɁA�u�S�̎d��������v������������ɑߕ߂����B
���[���b�p�̈�����̍ŏ��̊G�ł���A�w�_���X�}�J�u���x(1499-1500)���̖ؔłɁA�u�S�̎d��������v������������ɑߕ߂����B
Author:Urs APP
Last updated: 95/05/03