

 to Home Page
to Home Page
The Korean Tripitaka (Korean Buddhist canon) is well known not only because of its exceptional textual quality but also because its wooden printing plates still exist. Carved in the 13th century, the collection of more than 80.000 large double-sided printing blocks is housed in a building at one of Korea's most famous Zen (Son) monasteries, at Haeinsa. The collection, a Korean national treasure, is the oldest extant collection of wood blocks containing the entire Chinese Buddhist canon.

The history
At present, there are two main groups of workers
involved in the project:1) Around fifty people at the input center in downtown Seoul, employed and paid by Samsung. Their main job is the input of the whole canon. About forty are typists; the rest are editors, students in charge of character and variant lists, and engineers.
2) About half a dozen people employed by Haeinsa that work in another office in Seoul. They are mainly studying issues connected with the delivery of the data (data correction, search mechanisms, Internet, etc.)
Since the end of 1994, input is progressing at a fast pace. It is estimated that the basic input will be finished around November of 1995. The head of the Samsung team, a computer engineer, said that they will try to produce a CD-ROM by the first quarter of 1996. The Haeinsa team realizes that the correction of this enormous mass of electronic text might well take more than a decade, but following the lead of our ZenBase CD-ROM in releasing insufficiently corrected electronic texts as Al pha-versions, we may soon have the whole Tripitaka Koreana as Alpha-text.

The input facility in Seoul is impeccably clean, spacious, and well equipped. The input personnel is using good computers, manuscript holders, handrests, screen filters, etc. All computers are linked in a network to the engineer's office. Having seen various other input centers, I was quite impressed with the whole setup.
The first input tests in Shanghai four years ago had shown that it was not so much the sheer number of different Chinese characters but rather the Korean Tripitaka's abundant variant character forms that would pose the greatest problems for input. Should one create slightly different characters anew or simply "normalize" them even at the input level? After taking charge of the input project, the Samsung engineers decided to use a screen font that resembles the woodblock characters, thus eliminating many of the problems with Big-5 fonts from the outset. The principle is easily stated: the typists should see on screen what they see on paper, thus eliminating most decision making at the input level. Such decisions, experience had showed, corrupt the data because too many people with too many different opinions are involved.
As character code, the Samsung engineers decided to use a 16,000 character code from a Korean word processor. When it became clear that this was not sufficient, the code was augmented by close to 2,000 characters. Now that the basic input is nearing completion, a second batch of similar size is being added. The use of a not commonly used character code has some advantages; one is free to define characters and shapes according to the needs and can augment the number of ch
aracters as one pleases. At a later stage, conversion tables linking the Samsung code to the Taiwanese Big-5, the Japanese JIS, Unicode, etc. must be created. I was told that a KS code conversion table already exists; however, it was not clear how the many characters not present in KS would be handled. I would suggest that the For the input activity, Samsung hired and schooled about forty people (mostly female). The attractive screen font, combined with a Windows-based custom-made word processing progam and fast hardware and an input method of Chinese origin together provide an optimal environment. As they do on paper, screen characters appear in vertical lines, and editing text in the graphical user interface is easy.
The input system is based on shapes rather than pronunciation; the typist thus has to learn to associate certain shapes with certain keys on the keyboard. An average of around three keystrokes on an ordinary keyboard thus produces a Chinese character. For the most common characters or phrases, abbreviations can be created. The speed of the input is quite baffling.
For characters not available in the system,
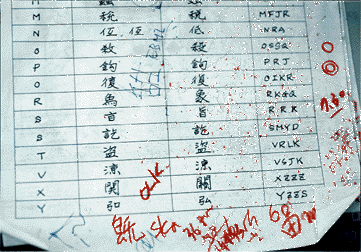
This photograph of a page with circles shows that even very common characters are marked as missing -- and this at a stage where more than two thirds of the whole canon are already input! Of course, periodical addition of missing characters to the available set would have eliminated most of these asterisks. Such missed opportunities tend to follow a general rule: what one fails to do in the first instance will take much longer afterwards. As the great number of asterisks in the data files indicats, the <
STRONG>elimination of asterisks will become a major headache. Quite unnecessarily so: instead of asterisks, one could simply leave the unsuccessful input code in the file, delimited by markers. At a later stage, characters with a single input code could be replaced automatically.
Furthermore, even a cursory glance showed that some of the marked characters were wrongly circled because they actually are present in the character set. The typist probably did not find it right away and input an asterisk. If speed is valued highly and supervision is not tight, such habits can become the rule rather than the exception. Looking at some of the input sheets, I found ample evidence of such habits; for example, the first character on the bottom right of the above photograph (Chinese "dun", s
udden) is certainly in the font set and could have been input. This led me to question the degree of quality control. The handling of variant forms Even if one would add screen characters for variants every day and hand them out on notes to the typists (as in the above photograph) or -- as I would do it -- in online documentation triggered by the input code, one would never come to an end. Indeed, the Tripitaka Koreana is so rich in variant forms that some people make this their field of study. In the present input project, Samsung employed a handful of students to note down "encircled" and variant characters on cards which are then catalogued.
Since the drawers of this sizable catalogue feature Hangul characters, I assume that the whole catalogue is sorted according to reading. However, the reading of variant forms and rare characters is often either unknown or difficult to figure out. Why not arrange them according to the shape-based input codes, thus also allowing the typists to consult it? One reason may be that the supervisor for variant characters is a Korean university professor who comes to Seoul once in a while and brings lists of "equ
ivalent" characters. He probably does not know how to type characters himself and thus cannot use input codes. It was not clear to me how strictly the directives of this professor are followed on the input level, but judging from the small number of variant characters noted down on the typist's desks, I had to assume that much of the "normalization" was also postponed to a later stage.
The question of the necessary degree of normalization Normalization of electronic text is thus essentially a software task; but one must make some preparations for this. If it were up to me, I would make online lists of scanned variant characters available to the typists so that they could simply click on the character that they actually see. This would then input the professor's proposed "normalized" character surrounded by a markup sequence indicating an identification number of the variant character. This would hardly cause more trouble to the typists(ju
st one more look at the screen and one more keystroke) but provide invaluable information for subsequent processing. First, it would liberate the overall quality of the data from the judgment of a single specialist. Second, it would allow subsequent batch correction. Third, it would facilitate producing various editions, among them one for use of researchers who are interested in variant characters. Fourth, and most importantly perhaps, it would immensely facilitate conversion into various present and futur
e codes. The Japanese JIS code, for example, contains a surprising number of variant characters; the Big-5 code tends to contain few of them; Unicode will contain a fair amount, and some future code (or one for specialists) may even feature them all. With appropriate software methodology, all of these interests can be served -- including some interests which we are not yet aware of. The normalization effort is certainly necessary, but it should not influence the basic data but rather be part of "processing"
the basic data for particular users and purposes. To use the image I employed in vol. 3 of the Electronic Bodhidharma: the input data should be like a master tape in music, superbly rich in information. This richness can later be reduced to serve particular needs and formats (such as audio cassettes). The path from more to less is easy; but, as any lover of Caruso recordings will confirm, that from less to more is hardly smooth.
Some of the problems pointed out above are due to the newness of the electronic medium Such descriptive markup would greatly facilitate subsequent work; for instance, files corresponding to texts could be generated completely automatically together with file names in Chinese character; or all variant character forms could be listed up by one command.
It is not yet clear how much the Samsung corporation wants to be involved in correcting and editing the data; however, I think that at least the first stage of data correction, the character-by-character comparison of the original text with a printout of the input data, should be considered part of the input task. A second or third stage, where people also read the text for content, could then be used to prepare for additional content-based markup using various color pencils: punctuation, names of person
s, names of buddhas and bodhisattvas, place names, names of texts, citations, comments, and so on.
Computer experts ought to play a prominent part in the first stages of markup and can build the foundation for good data quality. The more they know about electronic text and its particular elements, formats, and possibilities, the better their job will be done. This means that from the very first stage, scholars with experience in electronic text should be involved. As my evaluation of some aspects of this project proves, such consultation can potentially save thousands a
nd thousands of man-hours and significantly improve basic data quality. The more one moves towards content markup, however, the larger the role of traditional scholars of the field becomes. No computer expert can puncuate a classical Chinese Buddhist text, let alone perform more important markup. Much of this kind of markup can even be achieved by scholars unfamiliar with computers; equipped with a set of color pencils, one can much of this kind of work on paper.
Of course, collaboration between computer experts (who may know what is possible) and scholars (who have to grasp what is necessary) is essential all along.
Descriptive markup, if well planned and managed, can finally bring out the inherent advantages of electronic text, some of which we already know and many of which we still ignore. One of the most apparent ones, the ability to link chunks of data, could play a crucial role in linking canon information to dictionary information; thus one could, for example, search only texts translated by a specific person or of a specific time period or c
lick on a person's name to immediately get the relevant dictionary entry. At any rate, one thing is certain: the devoted monks and laymen who originally "input" the Korean Tripitaka on wood and made a prostration before carving every character, would never have dreamed of this new form that the fruit of their labor is now taking. In the light of their efforts, a dozen years of data correction and markup may appear less arduous a task. It is to them, too, that one owes an effort that produces an electronic e
dition whose quality assures survival for at least another millenium.



Author:Urs APP
Last updated: 95.10.23