Analyzing the categories of the Kanseki Repository
Table of Contents
1 Overview
In this paper, an attempt is made to see how the traditional categories for classifying literature in China compare to an analysis of the digital text in these categories. The research is done using the Kanseki Repository as an example.
2 Method
Most of the texts in the KR are not punctuated, and none of them are tokenized. To eliminate the problem of tokenization, for this research the tool sentencepiece is used.
Sentencepiece, developped by researchers at Google, Inc., uses stochastic methods to find the n most frequent adjoining character strings in a text. These adjoining strings, which are not words in any linguistic sense, are called "sentencepiece". In a training run, the tool will analyse the text and build a model of the text, including a list of the vocabulary (e.g. sentencepieces), which provides the pieces and the frequency of occurrence in the text corpus. This model can than be used to tokenize new texts into sentencepieces, the usual use case for this is building a pipeline for natural language processing. In this paper, however, the vocabulary lists will be used as a proxy for characteristics of the texts for comparison.
Apart from providing the text, the only piece of configuration needed for building the models, and the only one used here is the desired number of entries for the vocabulary list. The number of unique Kanji in the texts is usually around 11000, so the list should have more entries. In preparatory experiments, numbers ranging from 30000 to 120000 have been used, but it turned out that such large numbers are not productive, so for the run described here, only sizes of 30000 and 20000 have been used, to gauge what influence the vocabulary size might have on the outcome.
2.1 The vocabulary list
The KR is organized in 6 large categories, which each have subcategories of varying numbers, altogether there are 75 subcategories. Models have been builded separately for all categories with both vocabulary sizes. The resulting lists of 75 vocabulary lists in each run have then been consolidated into one global list of all sentencepieces in the corpus.
For each of these entries in the list, we recorded wich subcategories contained the entry. Some of the entries occur in all 75 subcategories, while most are only recorded in one. The number of co-occurrences across subcategories can be seen as an indicator of how specific or common a sentencepiece is. Figure 1 and 2 show a histogram of distributions1.
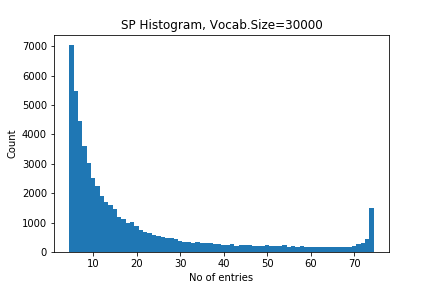
Figure 1: Vocabulary size distribution for vs=30000
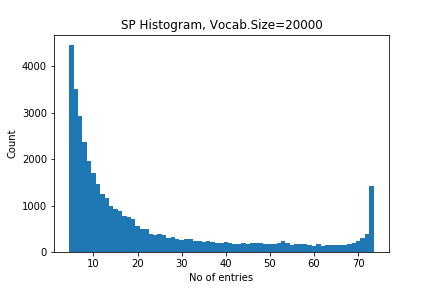
Figure 2: Vocabulary size distribution for vs=20000
2.2 From list to network
There are many ways to combine the vocabulary lists to form a network. Here we will consider every subcategory 部類 as a node, co-occurrence of two items in the vocabulary lists of two subcategory as an edge. The weight of this edge again can be calculated in different ways. Here we consider three possibilities:
- Count: Co-occurrences are simply counted: For every co-occurrence the weight counter for the edge between a node-pair is increased.
- Prob.: Probabilities of the two sentencepieces, as they occur in their respective subcategory. Here we simply add these probabilities.
- Pos: Position of the sentencepieces in the vocabulary list. Since the vocabulary list is sorted by probability, the position is an indicator of the probability, but increases much faster than the probability, thus we increase the scale, although in a non-linear manner. Here we assign the highest value to the first position and then decrease for every piece in the list. The combined value for position is the mean of the individual values.
In addition to using various values of weight for the network edges, we can also limit the edges based on how many subcategories they occur in. In the terms of Figure 1 and 2, we can consider an edge only relevant if it occurs more frequent or less frequent than a tresholds. We use different upper and lower limits, to see how the relative frequency of the co-occurrence contributes to forming a meaningful network.
3 Evaluation
3.1 Self/other score
It is difficult to evaluate the results of these calculations. As preliminary result, we did 18 calculations for different values of vocabulary size (20000 and 30000), upper and lower limits (70/35, 30/5, 3/1) and combined this with the above mentioned score for the weight of edges. Based on the proximity, for every subcategory, we list the 10 closest subcategories. As a first approximation (and since this is relative easy calculated), we consider how many subcategories from the same category for a given subcategory. From this, we produced 18 tables that list the Self/Other score and the 10 top subcategories for each of the values. For all subcategories 部類 in a category 部, for the 10 most similar subcategories, a same/other calculation is performed, the maximal score is thus 10 times the number of the subcategories for a given category.
In addition, to get a better overview, we created summary tables for all 6 top categories. These tables show how they perform in each calculation and allow for easier comparison.
3.2 Network analysis: Community detection
There are many ways to detect communities, that is, sub-networks with a strong mutual relation. Here we will use the louvain algorithm[1], which proved to be the best performing algorithm in [2]
4 Bibliograpy
[1] Blondel et.al (2008) Fast unfolding of communities in large networks
[2] Emmons et. al. (2016) Analysis of Network Clustering Algorithms and Cluster Quality Metrics at Scale