日本語の構文解析においては、3つのレベルでの「係り受け」が存在する。

いわゆる学校文法における句の「係り受け」は、文全体を少しずつ区切っていきながら、区切りにおける「係り受け」を考える、という点に大きな特徴がある。「係り受け」は一般に、文頭に近い方の句から文末の方へと係る。ただし、句の「係り受け」の中には「並置」と呼ばれる考え方があって、この場合は単に並べて図示される。[問2]の例では、たとえば「男性の名Alexanderの」は「愛称」に係っており、その中で「男性の名」と「Alexander」が並んでいて、さらにその中で「男性の」が「名」に係っている。ちなみに[問2]は、述部における「並置」構造、主部の共有、そして「女性の名Alexandraの愛称」における「並置」構造を読み解く問題だと考えられる。
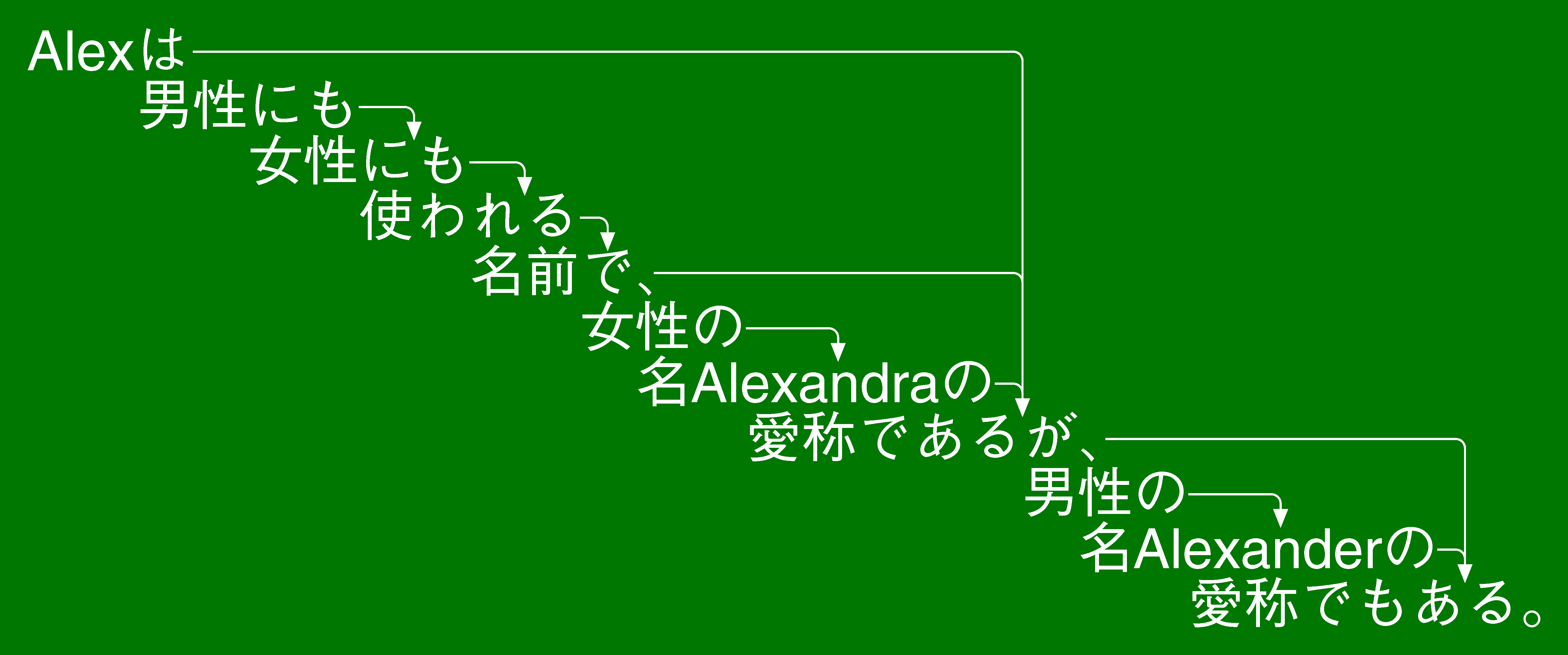
入力として与えられた日本文を、事前に文節に区切った上で、二文節間の「係り受け」を解析するやり方で、各文節の「係り受け」先を一つに限定している点に特徴がある。二文節間の「係り受け」は、文頭に近い方の文節から文末の方へと係る。「並置」も考慮せず、文頭の方から文末の方へと係る。[問2]の例では、たとえば「男性の」は「名Alexanderの」に係っており、「名Alexanderの」は「愛称でもある。」に係っている。ちなみに「東ロボくん」に使われているCaboChaは、二文節間の「係り受け」解析器であり、上記の図はCaboChaの出力結果である。
入力として与えられた文を、事前に単語に区切った上で、単語間の「係り受け」を有向グラフとして解析するやり方である。言語に限定されないよう、一貫して被修飾語から修飾語へリンク(矢印)が伸びることから、倒置文などに強い。各リンクには「係り受け」の種類を表すタグが付与されており、たとえば、述語から主語へ伸びるリンクはnsubjが、名詞による体言修飾にはnmodが付与される。名詞の「並置」は、それらが同一のものを指している場合にはapposが、そうでない場合はconjが付与される。なお、最先端のAI(ニューラルネットと機械学習)による「係り受け」解析エンジン(UniDic2UDやGiNZA)は、単語間の「係り受け」解析器を実装している。